浅谈 Redis 中间件
本博客主要是总结自己学习 Redis 中间件的经验,教程来源于b站狂神说 java 的 redis 教程
1、Redis 概念
1、Redis 是基于计算机内存的数据库,一般称为缓存数据库,由于没有固定的表结构与关系,也叫 NoSQL (Not Only SQL) 数据库。
2、为什么要使用 Redis:
- 1、数据的爆发增长
- 2、没有固定关系的数据
3、最新的版本中,官方不建议直接在 win 上使用操作 redis ,而是使用 WSL2 Linux 子系统进行 redis 的开发。
4、redis 常见使用场景
- 1、内存缓存
- 2、不想使用 kafka,可以作为消息队列而存在
- 3、做电商的热点数据保存,因为可以设置 TTL。
- 4、朋友圈点赞
- 5、做秒杀的库存
2、Redis bench-mark test
使用官方自带的 redis-benchmark 工具进行压力测试,其中
-h :host ,可以是本地,也能是远程进行压力测试
-p :port,即端口号
-c :connection,连接的熟练,基本上连接都是基于 tcp/socket 的。
-n:跟时间复杂度与空间复杂度差不多,即指定每一个连接数的请求次数。
redis-benchmark -h localhost -p 6379 -c 100 -n 10000
如果需要保存再一个日志文件中,也能使用 redis-benchmark -h localhost -p 6379 -c 100 -n 10000 > redis.log 命令
3、Redis 基本知识说明
redis 默认有 16 个数据库,默认是第 0 个数据库。
redis 的命令大小写不敏感,而其中的 key - value 大小写敏感。常见的命令有:
| 命令 | 效果 |
|---|---|
| select | 切换数据库 |
| dbsize | 查看数据库大小 |
| flushdb | 清空当前数据库所有 K-V 值 |
| flushall | 清空 redis 数据库中所有 K-V 值 |
redis 的限制跟 cpu 的性能无关,性能主要受制于硬件的内存与网络带宽。
4、Redis 中五大基本类型
String 类型
string 类型中常见的几种命令:
| 命令 | 效果 |
|---|---|
| keys * | 查询所有的 key 值 |
| type key | 查看 key 的类型 |
| exist key | 是否存在 key |
| append key value | 向 key 类型添加数据 |
| incr key | key 的 value 原子性 + 1 |
| decr key | key 的 value 原子性 - 1 |
| incrby key [numbers] | key 的 value 原子性 + numbers |
| decrby key [numbers] | key 的 value 原子性 - numbers |
| expire key [second] | 设置 key 的过期时间,默认是秒数 |
| getrange key start end | 取 key 的 value 从 start 到 end |
| setrange key offset val | 设置 key 的 value 的 offset 位后替换为 val |
| ttl key | 查看 key 剩余过期时间,默认是秒数 |
| setex key expire value | 设置 key value 以及过期时间 expire |
| setnx key value | 如果 key 不存在,则设置 value,存在则设置失败(分布式锁使用,乐观锁) |
| getset key value | 先得到 key 再设置 key value |
getset 命令有点类似于 CompareAndSwap 这种类型的值。
同理,还有 mset 、mget 为批量设置(非原子性),msetnx、msetex 等(原子性操作)
在 redis 中,如果要设计一种封装类型的对象,语法可以如下所示:
1、set user:1 {name:zhangsan, age : 18}
2、set user:1:name zhangsan user:1:age 18
string 常见的使用场景为:
- 1、计数器
- 2、统计多单位的数量
- 3、粉丝数
- 4、对象缓存存储
List类型
List 类型中常见的几种命令:
| 命令 | 效果 |
|---|---|
| keys * | 查询所有的 key 值 |
| lpush [listname] value | 将 value 插入 [listname] 队头 |
| lrange [listname] start end | 查看 [listname] 从队头的 start 到 end |
| lpop [listname] | 将 [listname] 队头的元素移除 |
| lindex [listname] index | 从队头开始索引第 index 个值 |
| rpush [listname] value | 将 value 插入 [listname] 队尾 |
| rrange [listname] start end | 查看 [listname] 从队尾的 start 到 end |
| rpop [listname] | 将 [listname] 队尾的元素移除 |
| rindex [listname] index | 从队尾开始索引第 index 个值 |
| llen [listname] | 查看 [listname] 长度 |
| lrem [listname] count value | 移除 [listname] 中 count 个值为 value 的值 |
| ltrim [listname] start end | 截断 [listname] 从 start 到 end |
List 底层实现就是一个双向链表,所以优点跟缺点都跟双向链表一样,具体可以学习相应数据结构的知识。程序员的内功还是 408 + 算法。
Set 类型
set 集合类型,里面的值不重复。其中一般的命令就不写如上面的表格型的命令,这里直接举例了:
- 1、sadd [setname] value :向 [setname] 添加 value
- 2、spop [setname] value :向 [setname] 删除 value
- 3、smembers [setname] :查看 [setname] 内所有值
- 4、sismember [setname] value :判断 value 是否存在 [setname] 中
- 5、srem [setname] value :移除 [setname] 中的 value
- 6、srandmember [setname] count :随机获取 [setname] 内一个值
- 7、smove source destination value :将 value 从 source 移动到 destination 去
- 8、sdiff [setname1] [setname2] :[setname1] 与 [setname2] 的差集
- 9、sinter [setname1] [setname2] :[setname1] 与 [setname2] 的交集
- 10、sunion [setname1] [setname2] :[setname1] 与 [setname2] 的并集
set 为一个无序、不重复集合。
Hash 类型
其实就是变为 key - map 结构,只是一个 map 集合。
hash 类型的命令大同小异,只是在基本操作前加一个 h。
如 hget、hset、hgetall、hlen、hexists、hmset 等。
其中独有的特性即是: hkeys 与 hvals 是只获取 k 或 v ,以及 hincrby、hdecrby 、hsetnx、hsetex 等命令。
虽然hash 与 string 很相似,但是从特点来看,hash 更适合存储结构体对象,string 更合适存储字符串类型。
Zset 类型
有序集合,set 基础之上增加了一个集合。常见命令也就是 zadd、zrange、zrangebyscore xxx -inf +inf (正负无穷的问题)、zcard(记个数)、zrem 删除、zcount 其中没有 ( 与 ) 即是闭区间,有 “( “ “)” 是开区间,比大小时候经常使用的方式如此。
zset 主要存储重要消息、带权重进行判断、排行榜的应用实现 Top N 测试。
当然更多的命令,可以前往 redis 的官网 进行查询命令,以及我们使用 go 、java 、cpp 等语言做开发的时候。用 java 的jredis、go 的go-redis,使用看文档即可。
程序设计最重要的是设计,程序是基石,设计是上层建筑,所以我们需要尽量把握设计的思想、代码的实现,这是很有重要性的概念。
以上即是五大基本数据类型,还有三种特殊的数据类型
5、Redis 中 三大特殊数据类型
geospatial
geospatial 在 redis 中 即是 geo,在 redis 3.x 版本就已经推出了,可以推算地理位置信息,两地之间的距离、方圆几里的人。
geo api 在现在的官网只有 9 个命令:geoadd、geopos、geodist、georadius。
其中 geo 的底层实现还是基于 zset,所以 zset 的命令都能操作 geo 数据结构。
如果不做地图地理信息的话,基本上项目内不会使用此数据类型
hyperloglog
hyperloglog 是基数统计的算法,用于网页的 UV 计数。
此数据结构占用内存非常小,只占用 $2^{64}$ B,即 12 KB 大小,所以从内存角度,Hyperloglog 是优先选择。
使用即是 pfadd、pfcount、pfmerge
bitmaps
位图,跟操作系统里面的一样,redis 里面可以统计用户信息:活跃、登陆、打开
操作为: setbit 、gerbit、bitcount
以上的数据结构了解使用即可,具体的原理,可以在工作中继续进行一个学习,现在我们主要学习其中的一个具体的场景即可。
6、redis 中的事务
在 Redis 中的单条命令保证原子性,而其事务是不保证原子性的! 事务的本质即是:一组命令的集合。事务具有一次性、顺序性、排他性。
redis 中的事务是没有隔离性的概念,没有隔离级别。
所有的命令在事务中没有被执行,必须发起执行命令时候,事务才能执行,即:exec 命令。
redis 事务执行方式:
- 开启事务 (multi)
- 命令入队,返回值均为 queue
- 执行事务 (exec)
事务也能放弃,命令即是:discard (即放弃事务队列里的所有命令)
以下两点异常需要注意
- 1、编译型异常:代码错误、错误命令,redis 事务队列不会去执行。
- 2、运行时异常:如果事务队列中存在语法性,那么执行命令的时候,只放弃命令命令错误的那几条。
- 3、注意:错误命令与命令错误这两种说法的区别
7、Redis 实现乐观锁
乐观锁:只会在更新数据的时候去判断一下,在此期间是否有修改过数据。
所以使用 watch 命令对 key 值进行监视即可。修改失败,用 unwatch 解锁,再 watch key,即可。
8、Go 连接操作 Redis 数据库
9、Redis.Conf 配置文件
redis.conf 需要重点理解一下。
redis 大小写不敏感在配置文件中已经说明了。
1 | |
10、AOF 与 RDB
在大部分情况下,RDB 是默认的持久化配置,大部分的情况下都够用了。
一般进行数据持久化的保存操作过程一般分为五步:
(1) 客户端向服务端发送写操作 (数据在客户端的内存中);
(2) 数据库服务端接收到写请求的数据 (数据在服务端的内存中);
(3) 服务端调用系统调用函数 write,将数据写入磁盘 (数据在系统内存的缓冲区中);
(4) 操作系统将缓冲区中的数据转移到磁盘控制器上 (数据在磁盘缓存中);
(5) 磁盘控制器将数据写到磁盘的物理介质中 (数据真正落到磁盘上);
以上五个步骤为在理想条件下,一个正常的保存流程。但是在大多数情况下,我们的机器等等都会有各种各样的故障,这里划分了两种情况:
1、Redis数据库发生故障,只要在上面的第三步执行完毕,那么就可以持久化保存,剩下的两步由操作系统替我们完成;
2、操作系统发生故障,必须上面 5 步都完成才可保存。
RDB
RDB (Redis DataBase) 操作是在内存中的数据库记录定时dump到磁盘上的RDB持久化。这种方式是就是将内存中数据以快照的方式写入到二进制文件中, 默认的文件名为 dump.rdb,下列代码与图为 RDB 的存储字节流的内容格式。

在执行 RDB 快照备份时候,一般会通过父进程,fork 一个子进程,将数据写到一个临时文件,快照写完后,替换原来的快照文件,子进程就退出,临时文件变成正式的 RDB 文件。
但是 RDB 对数据的完整性不敏感,最后一次持久化之后的数据在宕机后可能丢失。
RDB 文件默认的保存文件名称为 dump.rdb
RDB 的触发条件如下:
1、满足默认的 save 条件,会触发 rdb 规则
2、执行 flushall,也会触发 rdb 规则
3、退出 redis,也会产生 rdb 文件
RDB 的恢复条件如下:
1、将 dump.rdb 文件放在redis 启动目录即可,redis 会自动检查其中的数据并恢复
2、查看需要存在的位置: redis-cli 中 config get dir 即可。
rdb 适合大规模的数据恢复,但是需要一定的时间间隔进程操作。
RDB 具体更详细的内容请看此博客: RDB文件格式
AOF
AOF (Append Only File) ,记录服务器执行的 所有写操作 命令,类似于 Mysql 中的日志。在服务器启动时,通过重新执行 AOF 这些命令来还原数据集,相应的配置文件为 appendonly.aof,默认不开启,需要手动进行启动!
其他相应的配置可以查看 redis 的相应的conf 文件。比如 append async、auto-aof-rewrite-percentage、auto-aof-rewrite-min-size 等。
aof 文件大小大于 64mb 后就会产生重写的操作。
当 aof 文件出现问题时,需要使用 redis-check-aof --fix 工具对 aof 文件进行修复。
aof 同步设置:
- 1、每一次修改都会同步,文件的完整性会更好;
- 2、每 1s 同步一次,那么可能会丢失 1s 的数据;
- 3、不同步效率是最高的。
对比 aof 与 rdb,aof 是文件读写流操作,所以运行效率比rdb低,数据文件也比rdb大,修复数据的速度也比 rdb 慢。
Redis 还可以同时使用 AOF 持久化和 RDB 持久化。
在这种情况下, 当 Redis 重启时, 它会优先使用 AOF 文件来还原数据集, 因为 AOF 文件保存的数据集通常比 RDB 文件所保存的数据集更完整。
Redis 发布与订阅
发布订阅 ( pub / sub ) 是一种消息通信的模型,发送者发送消息,接收者接受消息。一般此模型涉及三种对象:
1、消息发送者
2、频道
3、消息订阅者
模型的视图如下:
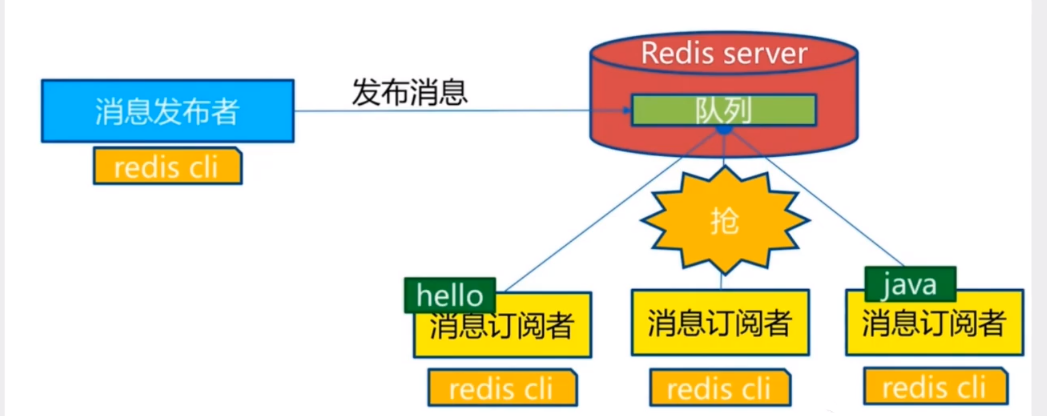
redis 的客户端可以订阅任意数量的频道,其相应的操作文档可以参考前文的 redis 官方文档,本博客只是介绍相应 redis pub / sub 模型的概念与原理。
Redis 主从复制
只要在企业中, Redis 集群是必用的,其架构通常为主从模式,一个主节点有多个从节点,一个从节点只有一个主节点。
主从复制的作用如下所示:
- 1、数据冗余:主从复制是可以热备份的,是区别于 redis 持久化的另外一种数据冗余的方式
- 2、故障恢复:当主节点出现问题时,可以由从节点提供服务,实现故障的快速恢复,也能称为服务冗余
- 3、负载均衡:主从架构主要是一种多读少写型的架构模式,通过多个 redis 服务器分担读的负载,可以大大提升 redis 服务器的并发量。
- 4、高可用的基石:主从复制是哨兵和集群能实施的基础,所以说是基石。
一般来说,单体 redis 服务器一旦发生单点故障,那么很有可能会丢失至少 1s 以上的数据,并且单体redis 需要处理所有的请求负载,压力较大。
而且,单体 redis 由于服务器的内存有限,不可能让服务器内存全部交给 redis 进行数据存储。单台 redis 内存占用不应超过 20GB 。
info replication 表示查看当前的 redis 服务器的角色信息
实现 redis 集群模式只需要修改三个配置属性即可,然后使用 redis 启动此三个配置即可:
- 1、端口
- 2、pid
- 3、log 文件名
配置从机时候,使用 slaveof + host + port 即可配置主从形式,但是一旦此redis 重启后,配置文件重置,若需要配置持久化的配置文件,需要手动设置 redis.conf 配置文件。具体可看 redis 的详细配置文件。
主从复制一般两种形式:全量复制与增量复制。其中,但凡从机只要是重新连接主机,都会发生一次全量复制。
本篇博客主要介绍相应的使用方法,浅谈一下原理,新开一个博客,用于自己对 redis 的底层源码与原理进行进一步的深入理解。