MySQL 原理
理解思考项目,原理先行,实践在后
1、redo-log 与 bin-log 两种日志区别
首先,redo-log 与 bin-log 两种日志是 InnoDB 数据库引擎为了满足事务的持久性与原子性引入了的,其中,redo-log 是 InnoDB 的特性,bin-log 是mysql 中 server 层的日志。
redo-log 日志
在更新一条记录时,先将其先写入 redo-log 中,然后更新内存,此时的记录就算更新完毕。等待数据库引擎空闲时,再将其更新至磁盘中。
而 redo-log 大小固定,由 innodb_log_file_size 设置大小和 innodb_log_files_in_group 设置个数,若要修改,则需重启服务。
一旦更新的数据条数达到 redo-log 日志记录数的上限,数据库引擎则先停止手中的活,将一部分的 redo-log 日志中的数据更新入磁盘,再继续运行。
本质上来说,redo-log 就是一个循环队列,如下图所示(原图来自极客时间专栏):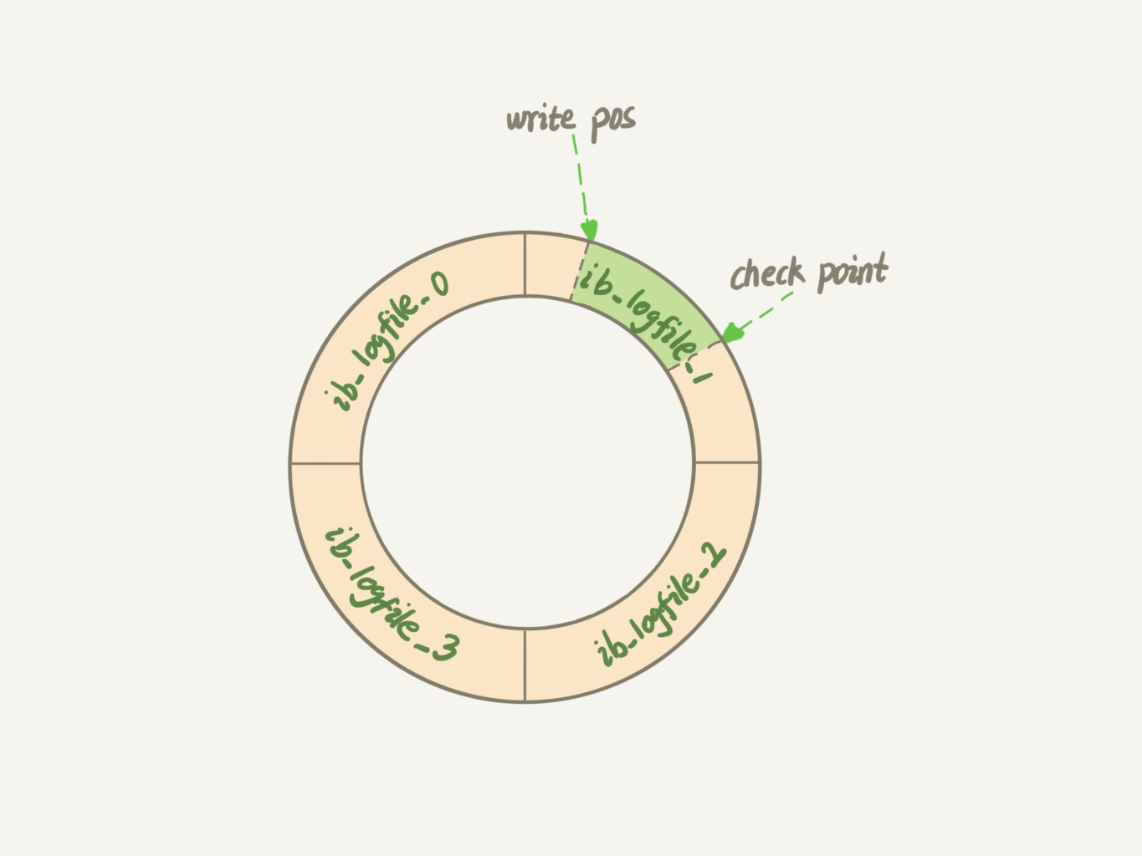
其中 witer_pos 为当前记录日志的地址,checkpoint 为当前要擦除的地址,擦除记录前需要将记录更新到数据库文件。
write_pos 和 checkpoint 之间的是 redo-log 空余的地址块,可以用来记录新的操作。如果 write pos 追上 checkpoint 即是 redo-log 记录操作已满,不能再执行新的更新,需要数据库引擎先擦除一些记录。
redo-log 可以防止因为数据库异常重启,而导致提交记录丢失的问题 – 这种特性称为 “crash-safe”
bin-log 日志
先介绍一下 bin-log 日志的背景:
最开始的时候,MySQL 中没有 InnoDB 数据库引擎,其自带的引擎为 MyISAM,而 MyISAM 没有 “crash-safe” 的能力,bin-log 日志只是归档记录的功能
现在来区别一下这两种日志:
1、redo-log 是 InnoDB 引擎特有 的;
bin-log 是 MySQL 的 Server 层实现的,所有引擎都可以使用。2、redo-log 是 物理日志,记录 “在某个数据页上的修改” ;
bin-log 是逻辑日志,记录的是这个语句的 原始逻辑;比如 “给 ID=2 这一行的 c 字段加 1 “。3、redo-log 是 循环写的,空间固定;
bin-log 是以 追加 的方式写入的。“追加写” 是 bin-log 文件达到一定大小后,会切换到下一个 bin-log 日志文件,并不会覆盖以前的日志。
所以可得到以下结论:
1、redo-log 的写盘时间会直接影响系统的吞吐,所以 redo-log 的数据量要尽量少。
2、由于系统崩溃的不确定性,重启重放 redo-log 文件时,系统不会知道,redo-log 中的那个 page 页已经修改入磁盘,所以 redo-log 的重放必须可以重入磁盘。
3、一般来说,建议一个 redo-log 只涉及一个内存 page 页来进行修改,这样就可以兼顾逻辑日志与物理日志的优势!
而 redo-log 提交是有两个阶段的:prepare 和 commit 阶段。
而之所以进行两个阶段的提交,也是为了达到 “crash-safe” 的目的。
情景
假设 redo-log 都是一次性提交,不分两个阶段,此时我们对一个字段 c 值进行更新,让 c 值从当前的 0,更新为 1。
情景1:我们先写 redo-log 后写 bin-log。假设在 redo log 写完,binlog 并未写完时,MySQL 进程异常重启。
redo log 写完之后,虽然系统崩溃也能将 MySQL 异常启动前的数据恢复回来。但是 bin-log 并未写完,此时记录的 bin-log 文件就没有记录之前操作的语句。
因此,在之后备份日志的 bin-log 也没有相应的操作语句。而若我们需要恢复临时库,由于 bin-log 记录的语句丢失,临时库恢复出来的这一行 c 的值就是 0,与原库的值不同。
情景2:我们先写 bin-log,后写 redo-log 假设在 binlog 写完,redo-log 并未写完时,MySQL 进程异常重启。
如果在 bin-log 写完之后,系统崩溃,由于 bin-log 不具备 “crash-safe” 的功能,而 redo-log 没写,所以崩溃恢复以后这个事务无效。
但是 bin-log 里面已经记录了”c 从 0 改为 1” 的日志。所以在之后用 bin-log 恢复临时库时,就会多出一个事务,恢复出来的 c 的值就是 1,与原库的值不同。
所以两阶段提交就是让这 redo-log 与 bin-log 两个状态保持逻辑上的一致。
针对于异常重启,在 MySQL 设置中的 innodb_flush_log_at_trx_commit、sync_binlog 均设置为 1,能保证 MySQL 异常重启之后数据不丢失与 bin-log 文件不丢失
一些补充
1、MySQL 的 bin-log 完整性
MYSQL 的 bin-log 拥有完整的形式:
1、statement 格式,最后会有 COMMIT;
2、row 格式,最后会有 XID event;
3、MySQL 5.6.5 版本后也引入了 bin-log checksum 用于验证 bin-log 内容的正确性,所以一旦 bin-log 所在的磁盘出现故障,可以通过验证 checksum 来确定准确性!
2、关于 bin-log 备份建议
一般性建议是一周一备份与一日一备份进行选择。看业务的评估,比如 RTO (恢复目标时间) 指标,一周一备份存储成本小,但是 RTO 长,而一日一备份,RTO 时间小,但是存储的成本大。
2、事务中的隔离性
事务概念:数据库在操作数据时,为了保证其逻辑的一致性的最小的单位,即是事务。
事务的特性:A (Atomicity)、C (Consistency)、I (Isolation)、D (Durablity) 即原子性、一致性、隔离性、持久性;
因此,事务是保持逻辑一致性、可恢复性的重要方法,而锁是保证事务的完整性与并发性的重要概念!
本次主要讲内容为隔离性。
隔离性的概念
隔离性的存在主要是为了区分多个事务并行执行的顺序问题,比如多个事务并行执行时,出现脏读、不可重复读,幻读等。
脏读:读取到其他的事物未提交的数据;
不可重复读:前后读取记录内容不一致;
幻读:前后读取记录数量不一致。
所以隔离性针对于以上的情况,分成如下几个级别的隔离:读未提交、读提交、可重复读与串行化
1、读未提交:一个事物还未提交,其所做的变更可以被其他事务读取
2、读提交:一个事务提交之后,其所做的变更才能被其他事务读取
3、可重复读:一个事务执行过程中看到的数据是一致的,未提交时其所做的变更对其余事务不可见!
4、串行化:对一个记录进行加读写锁,若其发生冲突,后访问的事务需要等前一个事务执行完毕时,才能继续执行。
上面四种情况,并行性逐步降低,但是安全性逐步升高!
Oracle 数据库的默认隔离级别是读提交,所以从 Oracle 数据库迁移到 MySQL 数据库中,需要设置 MySQL 的启动参数 transaction-isolation 的值设置成 READ-COMMITTED
MySQL 数据库默认的隔离级别是可重复读,但是可重复读会导致幻读的情况
隔离性的实现
在 MySQL 数据库中,为了控制并发执行的语句的顺序,引入了多版本分布式控制 MVCC (Mutiversion Concurrency Control)。
其具体内容可以概况如下:每条记录在更新的时候都会同时记录一条回滚日志:undo-log,同一条记录在系统中可以存在多个版本。抽象不好理解,可以看下图:
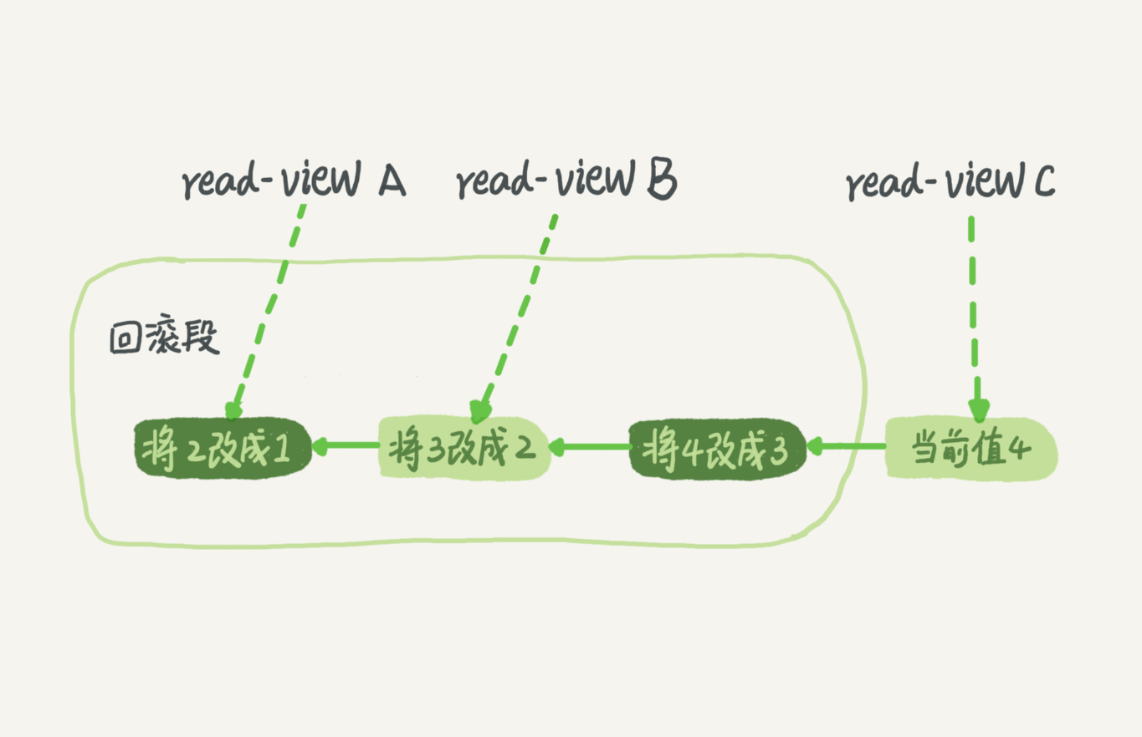
若我们需要将当前 4 的值恢复到 1 时,需要执行 3 次 undo-log 回滚。
而当系统中不存在比回滚日志更早的 read-view 时,undo-log 则会被删除。
以上图为例子,当 read-viewA 视图被删除后,将 3 改为 2 之前的 undo-log 即会被删除。
所以说一般开发时,MySQL 数据层的事务尽量避免过长。
事务的启动方式
MySQL 中的事务启动方式一般为两种
1、显式启动:使用 begin 或 start transaction。 配套的语句为 commit。回滚语句为 rollback
2、set autocommit = 0, 此命令会将线程自动关掉,只有手动执行上述两种配套的语句,才能进行一个事务的提交,或者断开连接时提交
所以建议使用 set autocommit = 1,通过显式语句来启动事务,而 commit 命令一般使用 commit work and chain 命令,即提交并且启动下一个事务。带来的效果是从程序开发的角度可以明确的知道每个语句是否存在于事务中!